6. Development¶
6.1. Architecture¶
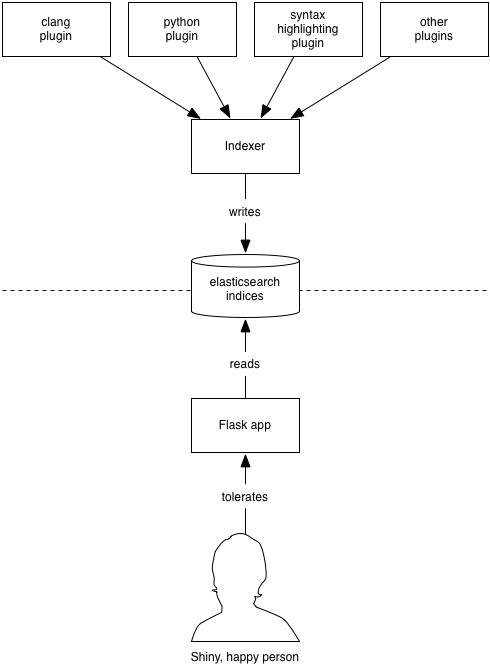
DXR divides into 2 halves, with stored indices in the middle:
The indexer, run via dxr index, is a batch job which analyzes code and builds indices in elasticsearch, one per tree, plus a catalog index that keeps track of them. The indexer hosts various plugins which handle everything from syntax coloring to static analysis.
Generally, the indexer is kicked off asynchronously—often even on a separate machine—by cron or a build system. It’s up to deployers to come up with strategies that make sense for them.
The second half is a Flask web application which lets users run queries. dxr serve runs a toy instance of the application for development purposes; a more robust method should be used for Deployment.
6.1.1. How Indexing Works¶
We store every line of source code as an elasticsearch document of type
line (hereafter called a “LINE doc” after the name of the constant used in
the code). This lends itself to the per-line search results DXR delivers. In
addition to the text of the line, indexed into trigrams for fast substring and
regex search, a LINE doc contains some structural data.
First are needles, search targets that structural queries can hunt for. For example, if we indexed the following Python source code, the indicated (simplified) needles might be attached:
def frob(): # py-function: frob nic(ate()) # py-callers: [nic, ate]
If the user runs the query
function:frob, we look for LINE docs with “frob” in their “py-function” properties. If the user runs the querycallers:nic, we look for docs with “py-callers” properties containing “nic”.These needles are offered up by plugins via the
needles_by_line()API. For the sake of sanity, we’ve settled on the convention of a language prefix for language-specific needles. However, the names are technically arbitrary, since the plugin emitting the needle is also its consumer, through the implementation of aFilter.Also attached to a LINE doc are offsets/metadata pairs that attach CSS classes and contextual menus to various spans of the line. These also come out of plugins, via
refs()andregions(). Views of entire source-code files are rendered by stitching multiple LINE docs together.
The other major kind of entity is the FILE doc. These support directory
listings and the storage of per-file rendering data like navigation-pane
entries (given by links()) or image contents.
FILE docs may also contain needles, supporting searches like ext:cpp which
return entire files rather than lines. Plugins provide these needles via
needles().
6.2. Setting Up¶
Here is the fastest way to get hacking on DXR.
6.2.1. Downloading DXR¶
Using git, clone the DXR repository:
git clone https://github.com/mozilla/dxr.git
6.2.2. Booting And Building¶
DXR runs only on Linux at the moment (and possibly other UNIX-like operating systems). The easiest way to get things set up is to use the included, preconfigured Docker setup. If you’re not running Linux on your host machine, you’ll need a virtualization provider. We recommend VirtualBox.
After you’ve installed VirtualBox (or ignored that bit because you’re on Linux), grab the three Docker tools you’ll need: docker, docker-compose, and, if you’re not on Linux, docker-machine. If you’re running the homebrew package manager on the Mac, this is as easy as…
brew install docker docker-compose docker-machine
Otherwise, visit the Docker Engine page for instructions.
Next, unless you’re already on Linux, you’ll need to spin up a Linux VM to host your Docker containers:
docker-machine create --driver virtualbox --virtualbox-disk-size 50000 --virtualbox-cpu-count 2 --virtualbox-memory 512 default
eval "$(docker-machine env default)"
Feel free to adjust the resource allocation numbers above as you see fit.
Note
Next time you reboot (or run make docker_stop), you’ll need to restart
the VM:
docker-machine start default
And each time you use a new shell, you’ll need to set the environment variables that tell Docker how to find the VM:
eval "$(docker-machine env default)"
When you’re done with DXR and want to reclaim the RAM taken by the VM, run…
make docker_stop
Now you’re ready to fire up DXR’s Docker containers, one to run elasticsearch and the other to interact with you, index code, and serve web requests:
make shell
This drops you at a shell prompt in the interactive container. Now you can build DXR and run the tests to make sure it works. Type this at the prompt within the container:
# Within the docker container...
make test
6.2.3. Running A Test Index¶
The folder-based test cases make decent workspaces for development, suitable
for manually trying out your changes. test_basic is a good one to start
with. To get it running…
cd ~/dxr/tests/test_basic
dxr index
dxr serve -a
If you’re using docker-machine, run docker-machine ip default to find
the address of your VM. Then surf to http://that IP address:8000/ from the
host machine, and explore the index. If you’re not using docker-machine,
the index should be accessible from http://localhost:8000/.
When you’re done, stop the server with Control-C.
6.3. Workflow¶
The repository on your host machine is mirrored over to the interactive
container via Docker volume mounting. Changes you make in the DXR repository on
your host machine will be instantly available within /home/dxr/dxr on the
container and vice versa, so you can edit using your usual tools on the host
and still use the container to run DXR.
After making changes to DXR, a build step is sometimes needed to see the effects of your work:
- Changes to C++ code or to HTML templates in the nunjucks folder:
make(at the root of the project)- Changes to the format of the elasticsearch index:
- Re-run
dxr indexinside your test folder (e.g.,tests/test_basic). Before committing, you should increment the format version.
Stop dxr serve, run any applicable build steps, and then fire up the server again. If you’re changing Python code that runs only at request time, you shouldn’t need to do anything; dxr serve will notice and restart itself a few seconds after you save.
6.4. Coding Conventions¶
Follow PEP 8 for Python code, but don’t sweat the line length too much. Follow PEP 257 for docstrings, and use Sphinx-style argument documentation. Single quotes are preferred for strings; use 3 double quotes for docstrings and multiline strings or if the string contains a single quote.
6.5. Testing¶
DXR has a fairly mature automated testing framework, and all server-side patches should come with tests. (Tests for client-side contributions are welcome as well, but we haven’t got the harness set up yet.)
6.5.1. Writing Tests for DXR¶
DXR supports two kinds of integration tests:
- A lightweight sort with a single file worth of analyzed code. This kind
stores the code as a Python string within a subclass of
SingleFileTestCase. At test time, it instantiates the file on disk in a temp folder, builds it, and makes assertions about it. If thestop_for_interactionclass variable is falsy (the default), it then deletes the index. If you want to browse the instance manually for troubleshooting, set this toTrue. - A heavier sort of test: a folder containing one or more source trees and a
DXR config file. These are useful for tests that require a multi-file tree
to analyze or more than one tree.
test_ignoresis an example. Within these folders are also one or more Python files containing subclasses ofDxrInstanceTestCasewhich express the actual tests. These trees can be built like any other usingdxr index, in case you want to do manual exploration.
6.5.2. Running the Tests¶
To run all the tests, run this from the root of the DXR repository (in the container):
make test
To run just the tests in tests/test_functions.py…
nosetests tests/test_functions.py
To run just the tests from a single class…
nosetests tests/test_functions.py:ReferenceTests
To run a single test…
nosetests tests/test_functions.py:ReferenceTests.test_functions
If you have trouble, make sure you didn’t mistranscribe any colons or periods.
To omit the often distracting elasticsearch logs that nose typically presents
when a test fails, add the --nologcapture flag.
6.6. Writing Plugins¶
Plugins are the way to add new types of analysis, indexing, searching, or display to DXR. In fact, even DXR’s basic capabilities, such as text search and syntax coloring, are implemented as plugins. Want to add support for a new language? A new kind of search to an existing language? A new kind of contextual menu cross-reference? You’re in the right place.
At the top level, a Plugin class binds together a
collection of subcomponents which do the actual work:
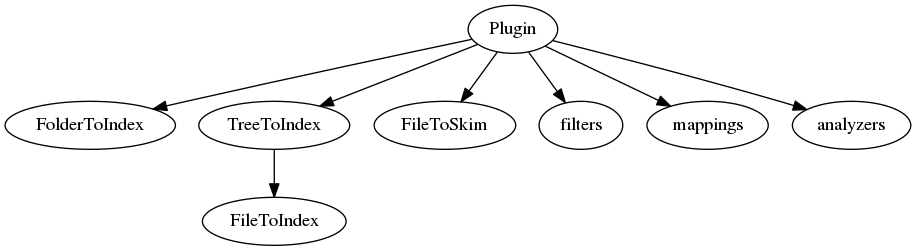
6.6.1. Registration¶
A Plugin class is registered via a setuptools entry point called dxr.plugins. For example, here are the
registrations for the built-in plugins, from DXR’s own setup.py:
entry_points={'dxr.plugins': ['urllink = dxr.plugins.urllink',
'buglink = dxr.plugins.buglink',
'clang = dxr.plugins.clang',
'omniglot = dxr.plugins.omniglot',
'pygmentize = dxr.plugins.pygmentize']},
The keys in the key/value pairs, like “urllink” and “buglink”, are the strings
the deployer can use in the enabled_plugins config directive to turn them
on or off. The values, like “dxr.plugins.urllink”, can point to either…
- A
Pluginclass which itself points to filters, skimmers, indexers, and such. This is the explicit approach—more lines of code, more opportunities to buck convention—and thus not recommended in most cases. ThePluginclass itself is just a dumb bag of attributes whose only purpose is to bind together a collection of subcomponents that should be used together. - Alternatively, an entry point value can point to a module which contains
the subcomponents of the plugin, each conforming to a naming convention by
which it can be automatically found. This method saves boilerplate and
should be used unless there is a compelling need otherwise. Behind the
scenes, an actual Plugin object is constructed implicitly: see
from_namespace()for details of the naming convention.
Here is the Plugin object’s API, in case you do decide to construct one manually:
- class
dxr.plugins.Plugin(filters=None, folder_to_index=None, tree_to_index=None, file_to_skim=None, mappings=None, analyzers=None, direct_searchers=None, refs=None, badge_colors=None, config_schema=None)[source]¶Top-level entrypoint for DXR plugins
A Plugin is an indexer, skimmer, filter set, and other miscellany meant to be used together; it is the deployer-visible unit of pluggability. In other words, there is no way to subdivide a plugin via configuration; there would be no sense running a plugin’s filters if the indexer that was supposed to extract the requisite data never ran.
If the deployer should be able to independently enable parts of your plugin, consider exposing those as separate plugins.
Note that Plugins may be instantiated multiple times; don’t assume otherwise.
Parameters:
- filters – A list of filter classes
- folder_to_index – A
FolderToIndexsubclass- tree_to_index – A
TreeToIndexsubclass- file_to_skim – A
FileToSkimsubclass- mappings – Additional Elasticsearch mapping definitions for all the plugin’s elasticsearch-destined data. A dict with keys for each doctype and values reflecting the structure described at http://www.elastic.co/guide/en/elasticsearch/reference/current/indices-put-mapping.html. Since a FILE-domain query will be promoted to a LINE query if any other query term triggers a line-based query, it’s important to keep field names and semantics the same between lines and files. In other words, a LINE mapping should generally be a superset of a FILE mapping.
- analyzers – Analyzer, tokenizer, and token and char filter definitions for the elasticsearch mappings. A dict with keys “analyzer”, “tokenizer”, etc., following the structure outlined at http://www.elastic.co/guide/en/elasticsearch/reference/current/analysis.html.
- direct_searchers –
Functions that provide direct search capability. Each must take a single query term of type ‘text’, return an elasticsearch filter clause to run against LINEs, and have a
direct_search_priorityattribute. Filters are tried in order of increasing priority. Return None from a direct searcher to skip it.Note
A more general approach may replace direct search in the future.
- refs – An iterable of
Refsubclasses supported by this plugin. This is used at request time, to turn abreviated ES index data back into HTML.- badge_colors – Mapping of Filter.lang -> color for menu badges.
- config_schema – A validation schema for this plugin’s configuration. See https://pypi.python.org/pypi/schema/ for docs.
mappingsandanalyzersare recursively merged into other plugins’ mappings and analyzers using the algorithm described atdeep_update(). This is mostly intended so you can add additional kinds of indexing to fields defined in the core plugin using multifields. Don’t go too crazy monkeypatching the world.
- classmethod
from_namespace(namespace)[source]¶Construct a Plugin whose attrs are populated by naming conventions.
Parameters: namespace – A namespace from which to pick components Filters are taken to be any class whose name ends in “Filter” and doesn’t start with “_”.
Refs are taken to be any class whose name ends in “Ref” and doesn’t start with “_”.
The tree indexer is assumed to be called “TreeToIndex”. If there isn’t one, one will be constructed which does nothing but delegate to the class called
FileToIndex(if there is one) whenfile_to_index()is called on it.The file skimmer is assumed to be called “FileToSkim”.
Mappings are pulled from
mappingsattribute and analyzers fromanalyzers.If these rules don’t suit you, you can always instantiate a Plugin yourself.
Actual plugin functionality is implemented within file indexers, tree indexers, folder indexers, filters, and skimmers.
6.6.2. Folder Indexers¶
6.6.3. Tree Indexers¶
-
class
dxr.indexers.TreeToIndex(plugin_name, tree, vcs_cache)[source]¶ A TreeToIndex performs build environment setup and teardown and serves as a repository for scratch data that should persist across an entire indexing run.
Instances must be pickleable so as to make the journey to worker processes. You might also want to keep the size down. It takes on the order of 2s for a 150MB pickle to make its way across process boundaries, including pickling and unpickling time. For this reason, we send the TreeToIndex once and then have it index several files before sending it again.
Parameters: - tree – The configuration of the tree to index: a TreeConfig
- vcs_cache – A
VcsCachethat describes any VCSes used by this tree. May be None if tree does not contain any VCS repositories.
-
environment(vars)[source]¶ Return environment variables to add to the build environment.
This is where the environment is commonly twiddled to activate and parametrize compiler plugins which dump analysis data.
Parameters: vars – A dict of the already-set variables. You can make decisions based on these. You may return a new dict or scribble on
varsand return it. In either case, the returned dict is merged into those from other plugins, with later plugins taking precedence in case of conflicting keys.
-
file_to_index(path, contents)[source]¶ Return an object that provides data about a given file.
Return an object conforming to the interface of
FileToIndex, generally a subclass of it.Parameters: - path – A path to the file to index, relative to the tree’s source folder
- contents – What’s in the file: unicode if we managed to guess an encoding and decode it, None otherwise
Return None if there is no indexing to do on the file.
Being a method on TreeToIndex, this can easily pass along the location of a temp directory or other shared setup artifacts. However, beware of passing mutable things; while the FileToIndex can mutate them, visibility of those changes will be limited to objects in the same worker process. Thus, a TreeToIndex-dwelling dict might be a suitable place for a cache but unsuitable for data that can’t evaporate.
If a plugin omits a TreeToIndex class,
from_namespace()constructs one dynamically. The method implementations of that class are inherited from this class, with one exception: afile_to_index()method is dynamically constructed which returns a new instance of theFileToIndexclass the plugin defines, if any.
6.6.4. File Indexers¶
-
class
dxr.indexers.FileToIndex(path, contents, plugin_name, tree)[source]¶ A source of search and rendering data about one source file
Analyze a file or digest an analysis that happened at compile time.
Parameters: - path – The (bytestring) path to the file to index, relative to the tree’s source folder
- contents – What’s in the file: unicode if we managed to guess at an
encoding and decode it, None otherwise. Don’t return any by-line
data for None; the framework won’t have succeeded in breaking up
the file by line for display, so there will be no useful UI for
those data to support. Think more along the lines of returning
EXIF data to search by for a JPEG. For unicode, split the file into
lines using universal newlines
(
dxr.utils.split_content_lines()); that’s what the rest of the framework expects. - tree – The
TreeConfigof the tree to which the file belongs
Initialization-time analysis results may be socked away on an instance var. You can think of this constructor as a per-file post-build step. You could do this in a different method, using memoization, but doing it here makes for less code and less opportunity for error.
FileToIndex classes of plugins may take whatever constructor args they like; it is the responsibility of their TreeToIndex objects’
file_to_index()methods to supply them. However, thepathandcontentsinstance vars should be initialized and have the above semantics, or a lot of the provided convenience methods and default implementations will break.-
needles()[source]¶ Return an iterable of key-value pairs of search data about the file as a whole: for example, modification date or file size.
Each pair becomes an elasticsearch property and its value. If the framework encounters multiple needles of the same key (whether coming from the same plugin or different ones), all unique values will be retained using an elasticsearch array.
-
needles_by_line()[source]¶ Return per-line search data for one file: for example, markers that indicate a function called “foo” is defined on a certain line.
Yield an iterable of key-value pairs for each of a file’s lines, one iterable per line, in order. The data might be data to search on or data stowed away for a later realtime thing to generate refs or regions from. In any case, each pair becomes an elasticsearch property and its value.
If the framework encounters multiple needles of the same key on the same line (whether coming from the same plugin or different ones), all unique values will be retained using an elasticsearch array. Values may be dicts, in which case common keys get merged by
append_update().This method is not called on symlink files, to maintain the illusion that they do not have contents, seeing as they cannot be viewed in file browsing.
FileToIndex also has all the methods of its superclass,
FileToSkim.
6.6.4.1. Looking Inside Elasticsearch¶
While debugging a file indexer, it can help to see what is actually getting
into elasticsearch. For example, if you are debugging
needles_by_line(), you can see all the data
attached to each line of code (up to 1000) with this curl command:
curl -s -XGET "http://localhost:9200/dxr_10_code/line/_search?pretty&size=1000"
Be sure to replace “dxr_10_code” with the name of your DXR index. You can see which indexes exist by running…
curl -s -XGET "http://localhost:9200/_status?pretty"
Similarly, when debugging needles(), you can
see all the data attached to files-as-a-whole with…
curl -s -XGET "http://localhost:9200/dxr_10_code/file/_search?pretty&size=1000"
6.6.5. File Skimmers¶
-
class
dxr.indexers.FileToSkim(path, contents, plugin_name, tree, file_properties=None, line_properties=None)[source]¶ A source of rendering data about a file, generated at request time
This is appropriate for unindexed files (such as old revisions pulled out of a VCS) or for data so large or cheap to produce that it’s a bad tradeoff to store it in the index. An instance of me is mostly an opportunity for a shared cache among my methods.
Parameters: - path – The (bytestring) conceptual path to the file, relative to the tree’s source folder. Such a file might not exist on disk. This is useful mostly as a hint for syntax coloring.
- contents – What’s in the file: unicode if we knew or successfully
guessed an encoding, None otherwise. Don’t return any by-line data
for None; the framework won’t have succeeded in breaking up the
file by line for display, so there will be no useful UI for those
data to support. In fact, most skimmers won’t be be able to do
anything useful with None at all. For unicode, split the file into
lines using universal newlines
(
dxr.utils.split_content_lines()); that’s what the rest of the framework expects. - tree – The
TreeConfigof the tree to which the file belongs
If the file is indexed, there will also be…
Parameters: - file_properties – Dict of file-wide needles emitted by the indexer
- line_properties – List of per-line needle dicts emitted by the indexer
-
absolute_path()[source]¶ Return the (bytestring) absolute path of the file to skim.
Note: in skimmers, the returned path may not exist if the source folder moved between index and serve time.
-
annotations_by_line()[source]¶ Yield extra user-readable information about each line, hidden by default: compiler warnings that occurred there, for example.
Yield a list of annotation maps for each line:
{'title': ..., 'class': ..., 'style': ...}
-
char_offset(row, col)[source]¶ Return the from-BOF unicode char offset for the char at the given row and column of the file we’re indexing.
This is handy for translating row- and column-oriented input to the format
refs()andregions()want.Parameters: - row – The 1-based line number, according to splitting in universal newline mode
- col – The 0-based column number
-
contains_text()[source]¶ Return whether this file can be decoded and divided into lines as text. Empty files contain text.
This may come in handy as a component of your own
is_interesting()methods.
-
is_interesting()[source]¶ Return whether it’s worthwhile to examine this file.
For example, if this class knows about how to analyze JS files, return True only if
self.path.endswith('.js'). If something falsy is returned, the framework won’t call data-producing methods likelinks(),refs(), etc.The default implementation selects only text files that are not symlinks. Note: even if a plugin decides that symlinks are interesting, it should remember that links, refs, regions and by-line annotations will not be called because views of symlinks redirect to the original file.
-
is_link()[source]¶ Return whether the file is a symlink.
Note: symlinks are never displayed in file browsing; a request for a symlink redirects to its target.
-
links()[source]¶ Return an iterable of links for the navigation pane:
(sort order, heading, [(icon, title, href), ...])
File views will replace any {{line}} within the href with the last-selected line number.
-
refs()[source]¶ Provide cross references for various spans of text, accessed through a context menu.
Yield an ordered list of extents and menu items:
(start, end, ref)
startandendare the bounds of a slice of a Unicode string holding the contents of the file. (refs()will not be called for binary files.)refis aRef.
-
regions()[source]¶ Yield instructions for syntax coloring and other inline formatting of code.
Yield an ordered list of extents and CSS classes (encapsulated in
Regioninstances):(start, end, Region)
startandendare the bounds of a slice of a Unicode string holding the contents of the file. (regions()will not be called for binary files.)
-
class
dxr.lines.Ref(tree, menu_data, hover=None, qualname=None, qualname_hash=None)[source]¶ Abstract superclass for a cross-reference attached to a run of text
Carries enough data to construct a context menu, highlight instances of the same symbol, and show something informative on hover.
Parameters: - menu_data – Arbitrary JSON-serializable data from which we can construct a context menu
- hover – The contents of the <a> tag’s title attribute. (The first one wins.)
- qualname – A hashable unique identifier for the symbol surrounded by this ref, for highlighting
- qualname_hash – The hashed version of
qualname, which you can pass instead ofqualnameif you have access to the already-hashed version
-
static
es_to_triple(es_data, tree)[source]¶ Convert ES-dwelling ref representation to a (start, end,
Refsubclass) triple.Return a subclass of Ref, chosen according to the ES data. Into its attributes “menu_data”, “hover” and “qualname_hash”, copy the ES properties of the same names, JSON-decoding “menu_data” first.
Parameters: - es_data – An item from the array under the ‘refs’ key of an ES LINE document
- tree – The
TreeConfigrepresenting the tree from which thees_datawas pulled
Return an iterable of menu items to be attached to a ref.
Return an iterable of dicts of this form:
{ html: the HTML to be used as the menu item itself href: the URL to visit when the menu item is chosen title: the tooltip text given on hovering over the menu item icon: the icon to show next to the menu item: the name of a PNG from the ``icons`` folder, without the .png extension }Typically, this pulls data out of
self.menu_data.
6.6.6. Filters¶
-
class
dxr.filters.Filter(term, enabled_plugins)[source]¶ A provider of search strategy and highlighting
Filter classes, which roughly correspond to the items in the Filters dropdown menu, tell DXR how to query the data stored in elasticsearch by
needles()andneedles_by_line(). An instance is created for each query term whosenamematches and persists through the querying and highlighting phases.This is an optional base class that saves code on many filters. It also serves to document the filter API.
Variables: - name – The string prefix used in a query term to activate this filter. For example, if this were “path”, this filter would be activated for the query term “path:foo”. Multiple filters can be registered against a single name; they are ORed together. For example, it is good practice for a language plugin to query against a language specific needle (like “js-function”) but register against the more generic “function” here. (This allows us to do language-specific queries.)
- domain – Either LINE or FILE. LINE means this filter returns results that point to specific lines of files; FILE means they point to files as a whole. Default: LINE.
- description – A description of this filter for the Filters menu:
unicode or Markup (in case you want to wrap examples in
<code>tags). Of filters having the same name, the description of the first one encountered will be used. An empty description will hide a filter from the menu. This should probably be used only internally, by the TextFilter. - union_only – Whether this filter will always be ORed with others of the same name, useful for filters where the intersection would always be empty, such as extensions
- is_reference – Whether to include this filter in the “ref:” aggregate filter
- is_identifier – Whether to include this filter in the “id:” aggregate filter
This is a good place to parse the term’s arg (if it requires further parsing) and stash it away on the instance.
Parameters: - term – a query term as constructed by a
QueryVisitor - enabled_plugins – an iterable of the enabled
Plugininstances, for use by filters that build upon the filters provided by plugins
Raise
BadTermto complain to the user: for instance, about an unparseable term.-
filter()[source]¶ Return the ES filter clause that applies my restrictions to the found set of lines (or files and folders, if
domainis FILES).To quietly do no filtration, return None. This would be suitable for
path:*, for example.To do no filtration and complain to the user about it, raise
BadTerm.We might even make this return a list of filter clauses, for things like the RegexFilter which want a bunch of match_phrases and a script.
-
highlight_content(result)[source]¶ Return an unsorted iterable of extents that should be highlighted in the
contentfield of a search result.Parameters: result – A mapping representing properties from a search result, whether a file or a line. With access to all the data, you can, for example, use the extents from a ‘c-function’ needle to inform the highlighting of the ‘content’ field.
-
highlight_path(result)[source]¶ Return an unsorted iterable of extents that should be highlighted in the
pathfield of a search result.Parameters: result – A mapping representing properties from a search result, whether a file or a line. With access to all the data, you can, for example, use the extents from a ‘c-function’ needle to inform the highlighting of the ‘content’ field.
6.6.7. Mappings¶
When you’re laying down data to search upon, it’s generally not enough just to
write needles() or
needles_by_line() implementations. If you want
to search case-insensitively, for example, you’ll need elasticsearch to fold
your data to lowercase. (Don’t fall into the trap of doing this in Python; the
Lucene machinery behind ES is better at the complexities of Unicode.) The way
you express these instructions to ES is through mappings and analyzers.
ES mappings are schemas which specify type of data (string,
int, datetime, etc.) and how to index it. For example, here is an excerpt of
DXR’s core mapping, defined in the core plugin:
mappings = {
# Following the typical ES mapping format, `mappings` is a hash keyed
# by doctype. So far, the choices are ``LINE`` and ``FILE``.
LINE: {
'properties': {
# Line number gets mapped as an integer. Default indexing is fine
# for numbers, so we don't say anything explicitly.
'number': {
'type': 'integer'
},
# The content of the line itself gets mapped 3 different ways.
'content': {
# First, we store it as a string without actually putting it
# into any ordered index structure. This is for retrieval and
# display in search results, not for searching on:
'type': 'string',
'index': 'no',
# Then, we index it in two different ways: broken into
# trigrams (3-letter chunks) and either folded to lowercase or
# not. This cleverness takes care of substring matching and
# accelerates our regular expression search:
'fields': {
'trigrams_lower': {
'type': 'string',
'analyzer': 'trigramalyzer_lower'
},
'trigrams': {
'type': 'string',
'analyzer': 'trigramalyzer'
}
}
}
}
},
FILE: ...
}
Mappings follow exactly the same structure as required by ES’s “put mapping” API. The choice of mapping types is also outlined in the ES documentation.
Warning
Since a FILE-domain query will be promoted to a LINE query if any other query term triggers a line-based query, it’s important to keep field names and semantics the same between lines and files. In other words, a LINE mapping should generally be a superset of a FILE mapping. Otherwise, ES will guess mappings for the undeclared fields, and surprising search results will likely ensue. Worse, the bad guesses will likely happen intermittently.
6.6.7.1. The Format Version¶
In the top level of the dxr package (not the top of the source
checkout, mind you) lurks a file called
format. Its role is to facilitate the automatic deployment of new
versions of DXR using dxr deploy. The format file contains an
integer which represents the index format expected by
dxr serve. If a change in the code requires a mapping or semantics
change in the index, the format version must be incremented. In response, the
deployment script will wait until new indices, of the new format, have been
built before deploying the change.
If you aren’t sure whether to bump the format version, you can always build an index using the old code, then check out the new code and try to serve the old index with it. If it works, you’re probably safe not bumping the version.
6.6.8. Analyzers¶
In Mappings, we alluded to custom indexing strategies, like breaking strings into lowercase trigrams. These strategies are called analyzers and are the final component of a plugin. ES has strong documentation on defining analyzers. Declare your analyzers (and building blocks of them, like tokenizers) in the same format the ES documentation prescribes. For example, the analyzers used above are defined in the core plugin as follows:
analyzers = {
'analyzer': {
# A lowercase trigram analyzer:
'trigramalyzer_lower': {
'filter': ['lowercase'],
'tokenizer': 'trigram_tokenizer'
},
# And one for case-sensitive things:
'trigramalyzer': {
'tokenizer': 'trigram_tokenizer'
}
},
'tokenizer': {
'trigram_tokenizer': {
'type': 'nGram',
'min_gram': 3,
'max_gram': 3
# Keeps all kinds of chars by default.
}
}
}
6.7. Contributing Documentation¶
We use Read the Docs for building and hosting the documentation, which uses sphinx to generate HTML documentation from reStructuredText markup.
To edit documentation:
- Edit
*.rstfiles indocs/source/in your local checkout. See reStructuredText primer for help with syntax.- Use
cd ~/dxr/docs && make htmlin the VM to preview the docs.- When you’re satisfied, submit the pull request as usual.
6.8. Troubleshooting¶
- Why is my copy of DXR acting erratic, failing at searches, making requests for JS templates that shouldn’t exist, and just generally not appearing to be in sync with my changes?
- Did you run
python setup.py installfor DXR at some point? Never, ever do that in development; usepython setup.py developinstead. Otherwise, you will end up with various files copied into your virtualenv, and your edits to the originals will have no effect. - How can I use pdb to debug indexing?
- In the DXR config file for the tree you’re building, add
workers = 0to the[DXR]section. That will keep DXR from spawning multiple worker processes, something pdb doesn’t tolerate well. - I pulled a new version of the code that’s supposed to have a new plugin (or I added one myself), but it’s acting like it doesn’t exist.
- Re-run
python setup.py developto register the new setuptools entry point.